Open-source
Version Control System
for Machine Learning Projects
 We’re onGitHub
We’re onGitHubDVC tracks ML models and data sets
DVC is built to make ML models shareable and reproducible. It is designed to handle large files, data sets, machine learning models, and metrics as well as code.
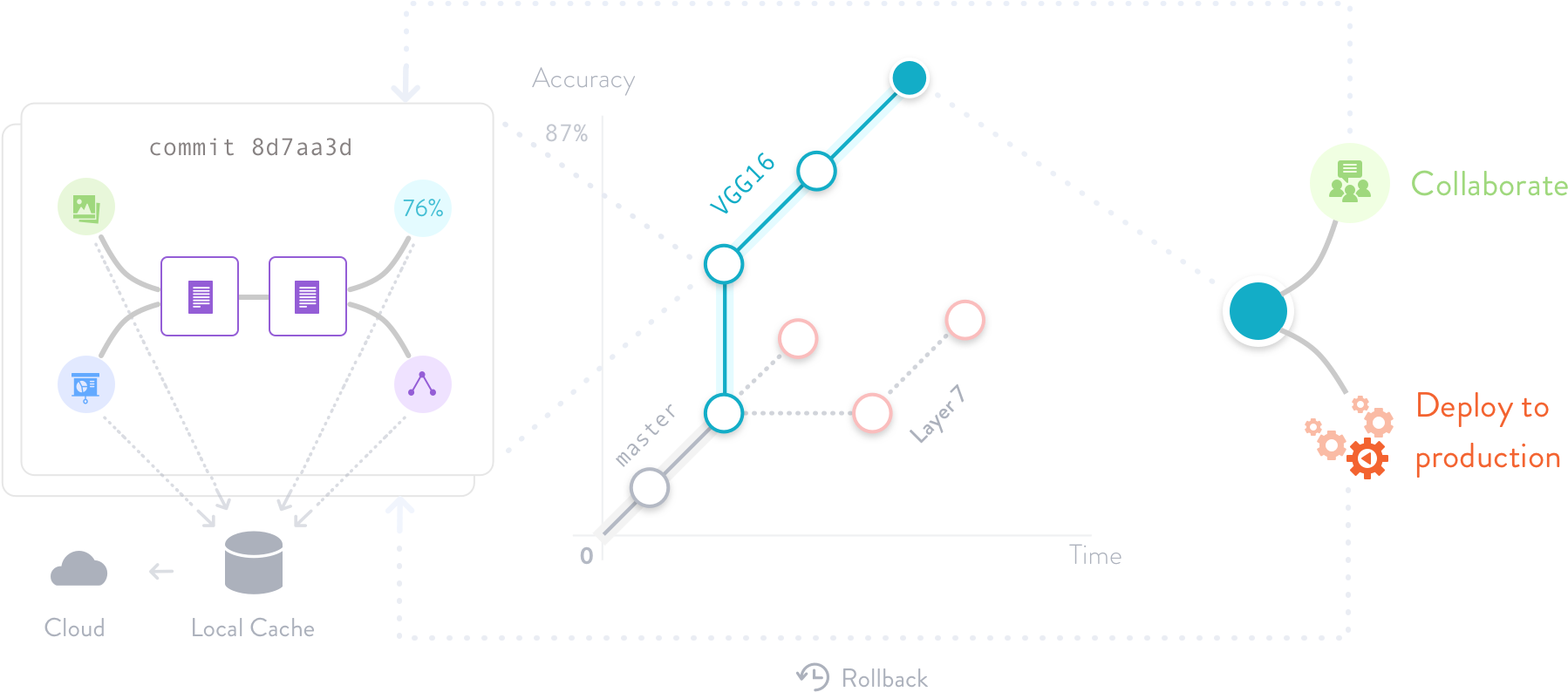
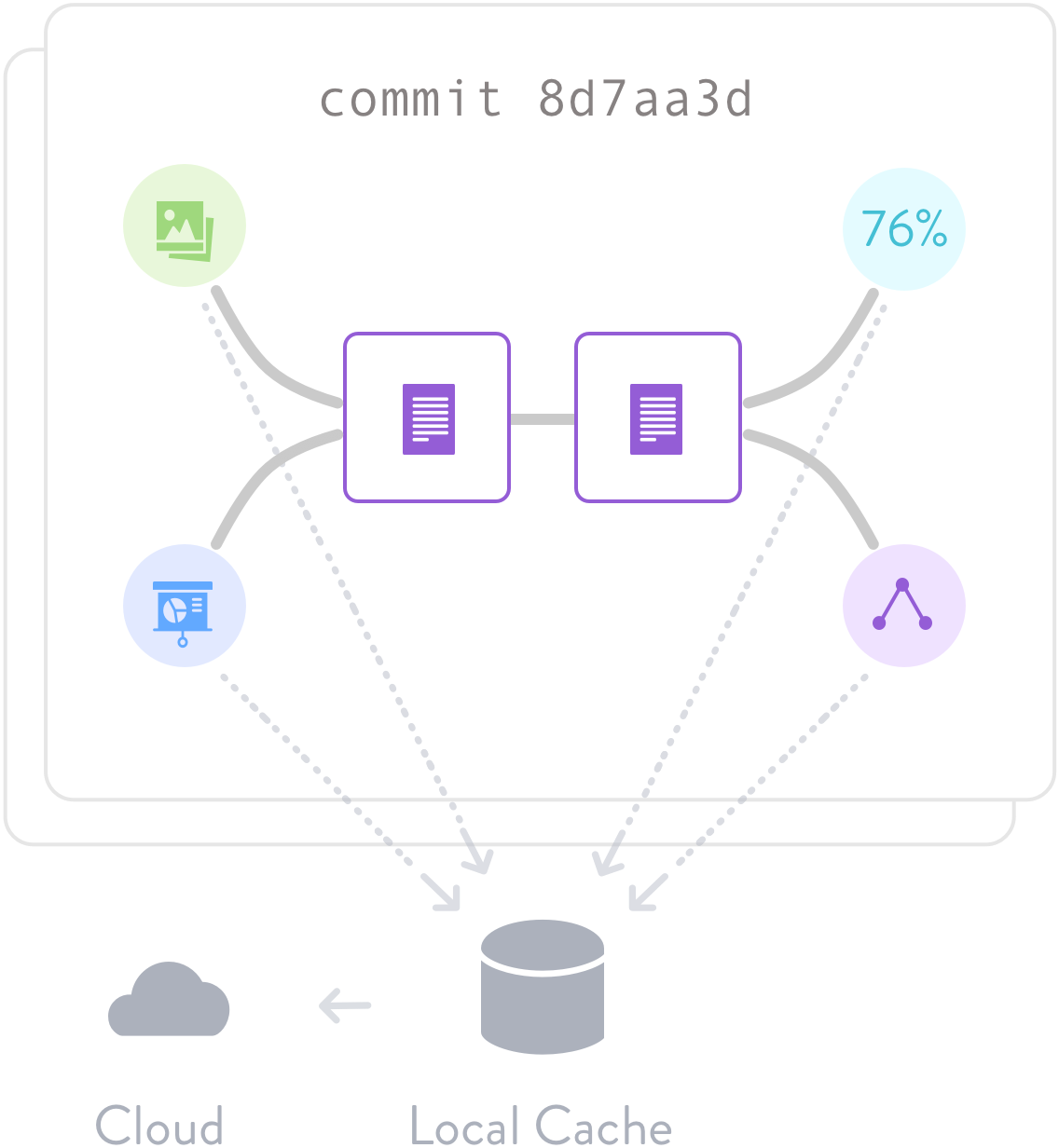
ML project version control
Version control machine learning models, data sets and intermediate files. DVC connects them with code, and uses Amazon S3, Microsoft Azure Blob Storage, Google Drive, Google Cloud Storage, Aliyun OSS, SSH/SFTP, HDFS, HTTP, network-attached storage, or disc to store file contents.
Full code and data provenance help track the complete evolution of every ML model. This guarantees reproducibility and makes it easy to switch back and forth between experiments.
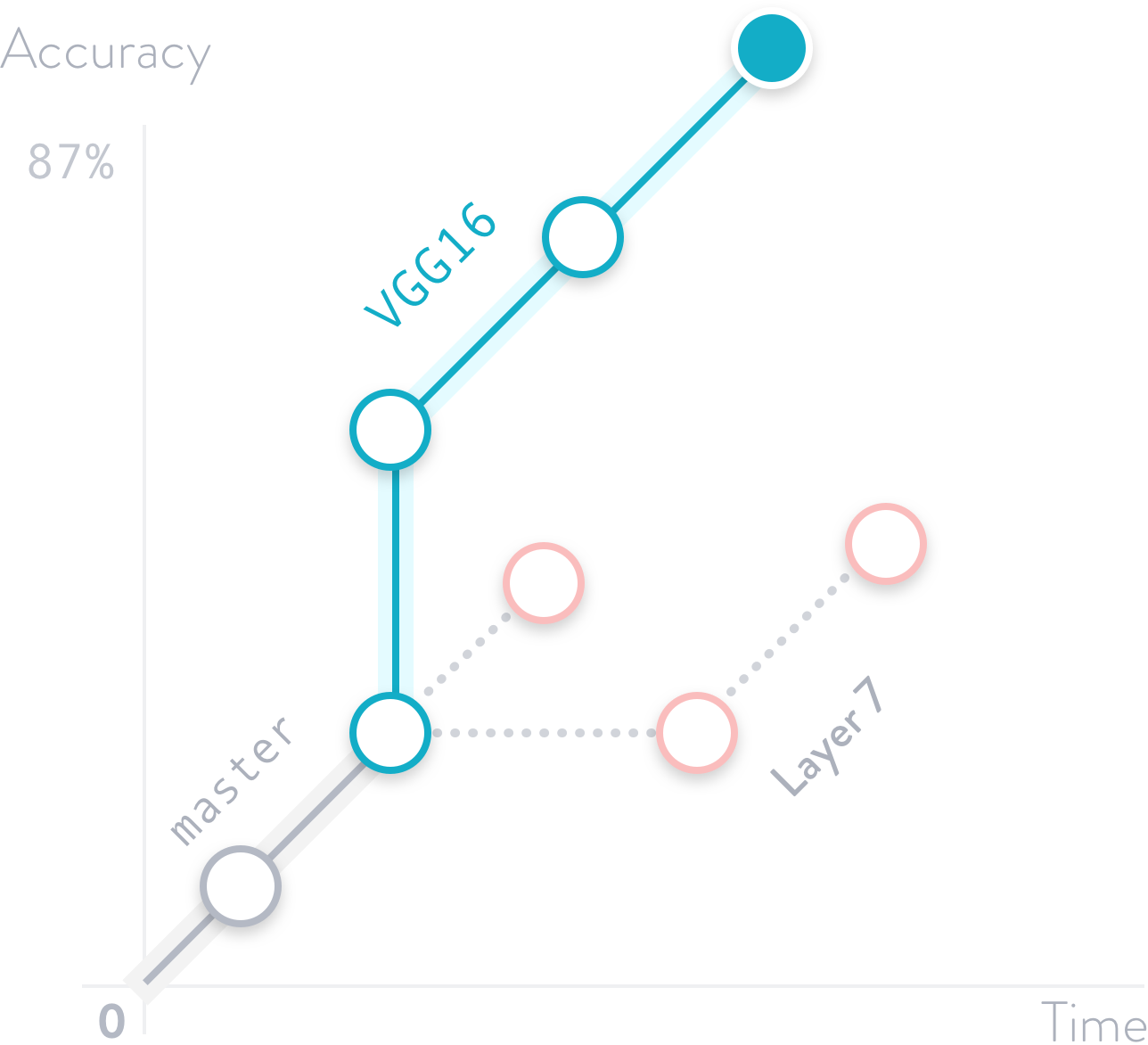
ML experiment management
Harness the full power of Git branches to try different ideas instead of sloppy file suffixes and comments in code. Use automatic metric-tracking to navigate instead of paper and pencil.
DVC was designed to keep branching as simple and fast as in Git — no matter the data file size. Along with first-class citizen metrics and ML pipelines, it means that a project has cleaner structure. It's easy to compare ideas and pick the best. Iterations become faster with intermediate artifact caching.
Deployment & Collaboration
Instead of ad-hoc scripts, use push/pull commands to move consistent bundles of ML models, data, and code into production, remote machines, or a colleague's computer.
DVC introduces lightweight pipelines as a first-class citizen mechanism in Git. They are language-agnostic and connect multiple steps into a DAG. These pipelines are used to remove friction from getting code into production.
ML experiment management
Harness the full power of Git branches to try different ideas instead of sloppy file suffixes and comments in code. Use automatic metric-tracking to navigate instead of paper and pencil.
DVC was designed to keep branching as simple and fast as in Git — no matter the data file size. Along with first-class citizen metrics and ML pipelines, it means that a project has cleaner structure. It's easy to compare ideas and pick the best. Iterations become faster with intermediate artifact caching.

For data scientists, by data scientists

Use cases
Save and reproduce your experiments
Version control models and data
Establish workflow for deployment & collaboration
Save and reproduce your experiments
Version control models and data
Establish workflow for deployment & collaboration

