September ’19 DVC❤️Heartbeat
Every month we are sharing here our news, findings, interesting reads, community takeaways, and everything along the way.
Some of those are related to our brainchild DVC and its journey. The others are a collection of exciting stories and ideas centered around ML best practices and workflow.


News and links
We are super excited to co-host our very first meetup in San Francisco on October 10! We will gather at the brand new Dropbox HQ office at 6:30 pm to discuss open-source tools to version control ML models and experiments. Dmitry Petrov is teaming up with Daniel Fischetti from Standard Cognition to discuss best ML practices. Join us and save your spot now:

If you are not in SF on this date and happen to be in Europe — don’t miss the PyCon DE & PyData Berlin 2019 joint event on October 9–11. We cannot make it to Berlin this year, but we were thrilled to discover 2 independent talks featuring DVC by Alessia Marcolini and Katharina Rasch.
Some other highlights of the end of summer:
- Our users and contributors keep creating fantastic pieces of content around DVC (sharing some links below, but it’s only a fraction of what we have in stock — can’t be more happy and humbled about it!).
- We’ve reached 79 contributors to DVC core project and 74 contributors to DVC documentation (and have something special in mind to celebrate our 100th contributors).
- We enjoyed working with all the talented Google Season of docs applicants and now moving to the next stage with our chosen tech writer Dashamir Hoxha.
-
We’ve crossed the 3,000 stars mark on Github (over 3,500 now). Thank you for your support!
https://t.co/vhkN3zWzjT just hit 3000 stars on #Github! https://t.co/AILppwghuu
— 🦉DVC (@DVCorg) July 5, 2019
Thank you for your trust, your contributions and your insights🤝
We are beyond happy to have you with us on this exciting journey🚀 pic.twitter.com/dwokD2v7t7 -
We’ve had great time at the Open Source Summit by Linux foundation in San Diego — speaking on stage, running a booth and chatting with all the amazing open-source crowd out there.
Love all @DVCorg booth buzz at #OSSummit! 🎉
— Svetlana Grinchenko (@a142hr) August 21, 2019
Stop by and grab some cool swag 🌈and participate in our easy fun contest to win a Jetson Nano, the coolest fuzzy owls and a bunch of other staff! 🤩 pic.twitter.com/MIzfilhrRJ

Here are some of the great pieces of content around DVC and ML ops that we discovered in July and August:
-
** Great insightful discussion on Twitter about versioning ML projects started by Nathan Benaich.**
🙏Question to ML friends: How do you go about version control for your ML projects (data, models, and intermediate steps in your data pipelines)? Have you built your own tools? Are using something open source? Or a SaaS? Or does this come bundled with your ML infra products? Thx!
— Nathan Benaich (@nathanbenaich) July 18, 2019 - Our Machine Learning Workflow: DVC, MLFlow and Training in Docker Containers by Ward Van Laer.
It is possible to manage your work flow using open-source and free tools.

DVC brought versioning for inputs, intermediate files and algorithm models to the VAT auto-detection project and this drastically increased our productivity.

- Managing versioned machine learning datasets in DVC, and easily share ML projects with colleagues by David Herron.
In this tutorial we will go over a simple image classifier. We will learn how DVC works in a machine learning project, how it optimizes reproducing results when the project is changed, and how to share the project with colleagues.

To illustrate the use of dvc in a machine learning context, we assume that our data is divided into train, test and validation folders by default, with the amount of data increasing over time either through an active learning cycle or by manually adding new data.

This post presents a solution to version control machine learning models with git and dvc (Data Version Control).
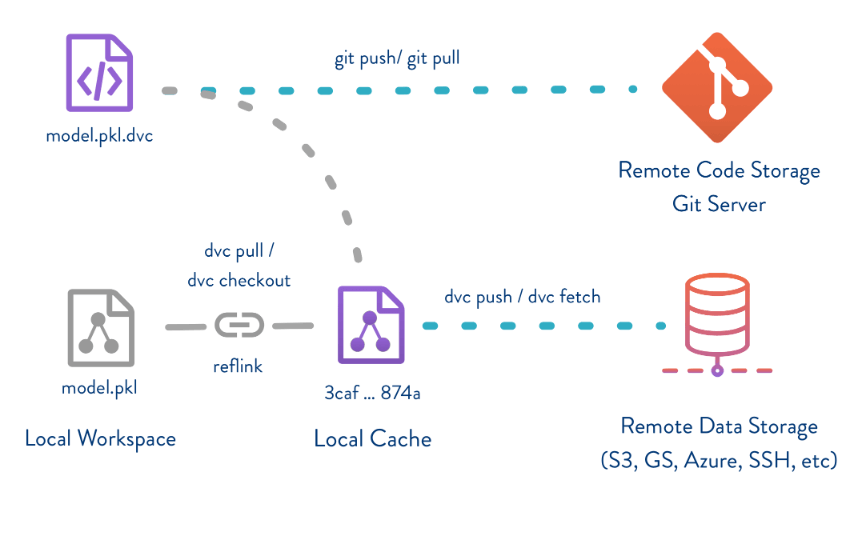
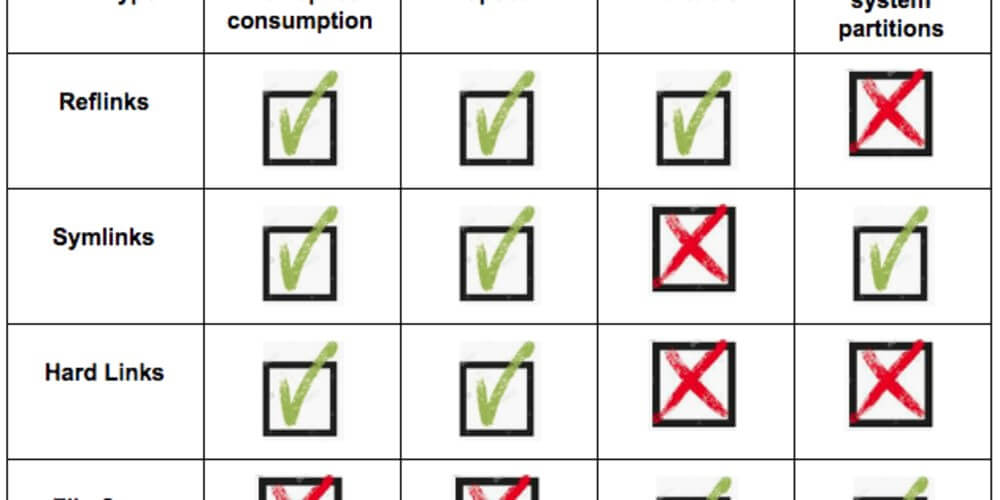
In this blog post we’ll go over the details of using links, some cool new stuff in modern file systems (reflinks), and an example of how DVC (Data Version Control, https://dvc.org/) leverages this.
This post is a follow-up to A walkthrough of DVC that deals with managing dependencies between DVC projects. In particular, this follow-up is about importing specific versions of an artifact (e.g. a trained model or a dataset) from one DVC project into another.

In this post I’ll present lessons learned on how to setup successful ML teams and what you need to devise an effective enterprise ML strategy.
Setting up a documentation-by-design workflow and using appropriate tools where needed, e.g. MLFlow and dvc, can be a real deal-breaker.

Discord gems
There are lots of hidden gems in our Discord community discussions. Sometimes they are scattered all over the channels and hard to track down.
We are sifting through the issues and discussions and share with you the most interesting takeaways.
Q: I’m getting an error message while trying to use AWS S3 storage: ERROR: failed to push data to the cloud — Unable to locate credentials. Any ideas what’s happening?
Most likely you haven’t configured your S3 credentials/AWS account yet. Please, read the full documentation on the AWS website. The short version of what should be done is the following:
- Create your AWS account.
- Log in to your AWS Management Console.
- Click on your user name at the top right of the page.
- Click on the Security Credentials link from the drop-down menu.
- Find the Access Credentials section, and copy the latest
Access Key ID. - Click on the Show link in the same row, and copy the
Secret Access Key.
Follow this link to setup your environment.
Q: I added data with dvc add or dvc run and see that it takes twice what it was before (with du command). Does it mean that DVC copies data that is added under its control? How do I prevent this from happening?
To give a short summary — by default, DVC copies the files from your working directory to the cache (this is for safety reasons, it is better to duplicate the data). If you have reflinks (copy-on-write) enabled on your file system, DVC will use that method — which is as safe as copying. You can also configure DVC to use hardlinks/symlinks to save some space and time, but it will require enabling the protected mode (making data files in workspace read-only). Read more details here.
Q: How concurrent-friendly is the cache? And different remotes? Is it safe to have several containers/nodes fill the same cache at the same time?
It is safe and a very common use case for DVC to have a shared cache. Please, check this thread, for example.
Q:What is the proper way to exit the ASCII visualization? (when you run dvc pipeline show command).
See this document. To navigate, use arrows or W, A, S, D keys. To exit, press Q.
Q: Is there an issue if I set my cache.s3 external cache to my default remote? I don’t quite understand what an external cache is for other than I have to have it for external outputs.
Short answer is that we would suggest keeping them separately to avoid possible checksum overlaps. Checksum on S3 might theoretically overlap with our checksums (with the content of the file being different), so it could be dangerous. The chances of losing data are pretty slim, but we would not risk it. Right now, we are working on making sure there are no possible overlapping.
Q: What’s the right procedure to move a step .dvc file around the project?
Assuming the file was created with dvc run. There are few possible ways.
Obvious one is to delete the file and create a new one with
dvc run --no-exec -f file/path/and/name.dvc. Another possibility is to
rename/move and then edit manually. See
this document that describes
how DVC-files are organized. No matter what method you use, you can run
dvc commit file.dvc to save changes without running the command again.
Q: dvc status doesn’t seem to report things that need to be dvc pushed, is that by design?
You should try with dvc status --cloud or dvc status --remote <your-remote>
to compare your local cache with a remote one, by default it only compares the
“working directory” with your local cache (to check whether something should be
reproduced and saved or not).
Q: What kind of files can you put into dvc metrics?
The file could be in any format, dvc metrics show will try to interpret the
format and output it in the best possible way. Also, if you are using csv or
json, you can use the --xpath flag to query specific measurements. In
general, you can make any file a metric file and put any content into it, DVC is
not opinionated about it. Usually though these are files that measures the
performance/accuracy of your model and captures configuration of experiments.
The idea is to use dvc metrics show to display all your metrics across
experiments so you can make decisions of which combination (of features,
parameters, algorithms, architecture, etc.) works the best.
Q: Does DVC take into account the timestamp of a file or is the MD5 only depends on the files actual/bits content?
DVC takes into account only content (bits) of a file to calculate hashes that are saved into DVC-files.
Q: Similar to dvc gc is there a command to garbage collect from the remote?
dvc gc --remote NAME is doing this, but you should be extra careful, because
it will remove everything that is not currently “in use” (by the working
directory). Also, please check this
issue — semantics of this
command might have changed by the time you read this.
Q: How do I use and configure remote storage on IBM Cloud Object Storage?
Since it’s S3 compatible, specifying endpointurl (exact URL depends on the
region)
is the way to go:
$ dvc remote add -d mybucket s3://path/to/dir
$ dvc remote modify mybucket \
endpointurl \
https://s3.eu.cloud-object-storage.appdomain.cloudQ: How can I push data from client to google cloud bucket using DVC?. Just want to know how can i set the credentials.
You can do it by setting environment variable pointing to yours credentials path, like:
$ export GOOGLE_APPLICATION_CREDENTIALS=path/to/credentialsIt is also possible to set this variable via dvc config:
$ dvc remote modify myremote credentialpath /path/to/my/credswhere myremote is your remote name.
If you have any questions, concerns or ideas, let us know in the comments below or connect with DVC team here. Our DMs on Twitter are always open, too.

