What Is DVC?
Data Version Control is a new type of data versioning, workflow, and experiment management software, that builds upon Git (although it can work stand-alone). DVC reduces the gap between established engineering tool sets and data science needs, allowing users to take advantage of new features while reusing existing skills and intuition.
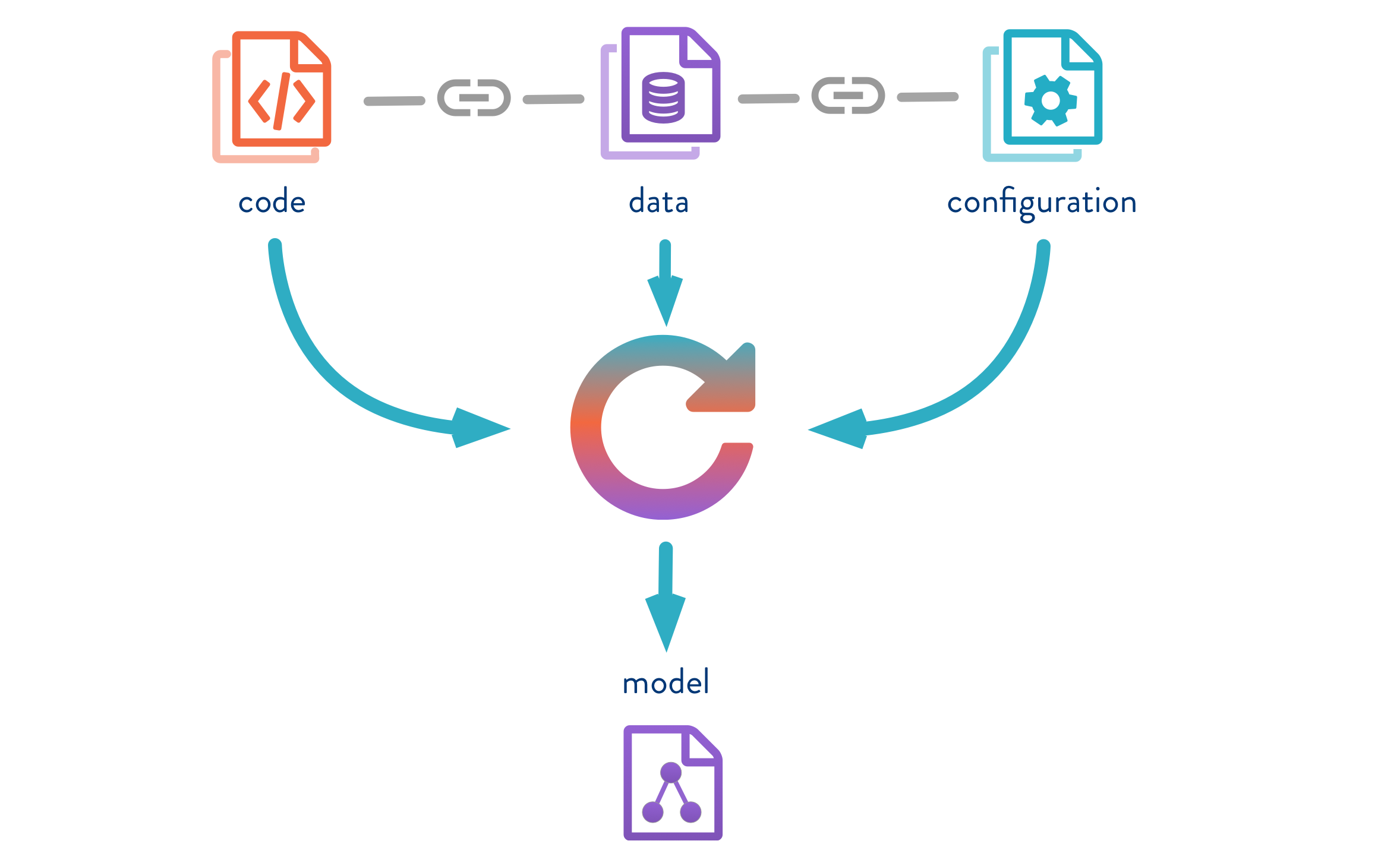 DVC codifies data and ML experiments
DVC codifies data and ML experiments
Data science experiment sharing and collaboration can be done through a regular Git flow (commits, branching, pull requests, etc.), the same way it works for software engineers. Using Git and DVC, data science and machine learning teams can version experiments, manage large datasets, and make projects reproducible.
Core Features
- DVC is a free, open-source command line tool.
- DVC works on top of Git repositories and has a similar command line interface and flow as Git. DVC can also work stand-alone, but without versioning capabilities.
- Data versioning is enabled by replacing large files, dataset directories, machine learning models, etc. with small metafiles (easy to handle with Git). These placeholders point to the original data, which is decoupled from source code management.
- Data storage: On-premises or cloud storage can be used to store the project's data separate from its code base. This is how data scientists can transfer large datasets or share a GPU-trained model with others.
- DVC makes data science projects reproducible by creating lightweight pipelines using implicit dependency graphs, and by codifying the data and artifacts involved.
- DVC is platform agnostic: It runs on all major operating systems (Linux, MacOS, and Windows), and works independently of the programming languages (Python, R, Julia, shell scripts, etc.) or ML libraries (Keras, Tensorflow, PyTorch, Scipy, etc.) used in the project.
-
Easy to use: DVC is quick to install and doesn't require special infrastructure, nor does it depend on APIs or external services. It's a stand-alone CLI tool.
Git servers, as well as SSH and cloud storage providers are supported, however.
DVC does not replace Git!
DVC metafiles such as dvc.yaml and .dvc files serve as placeholders to track
large data files and directories for versioning (among other
purposes). These metafiles change
along with your data, and you can use Git to place them under
version control
as a proxy to the actual data versions, which are stored in the DVC
cache (outside of Git). This does not replace features of Git.
DVC does, however, provide several commands similar to Git such as dvc init,
dvc add, dvc checkout, or dvc push, which interact with the underlying Git
repo (if one is being used, which is not required).